
App will soon be removed
The AI Assistant for Confluence will be discontinued and removed 1. May 2026 and no longer be working.
Atlassian applies a timeout limit of 25 seconds during requests to ChatGPT for forge apps. If a response from ChatGPT is especially lengthy, it can result in an excessive token count that surpasses the definitive limits, leading to a potential request timeout error.
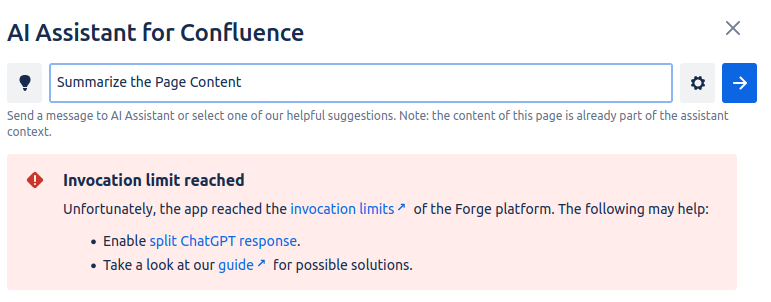
However, we provide certain options that you can activate to efficiently manage your requests and ensure smooth and consistent operation of the client.
Configuring the Options
You can access these options by clicking the gear icon situated near the 'send' button.
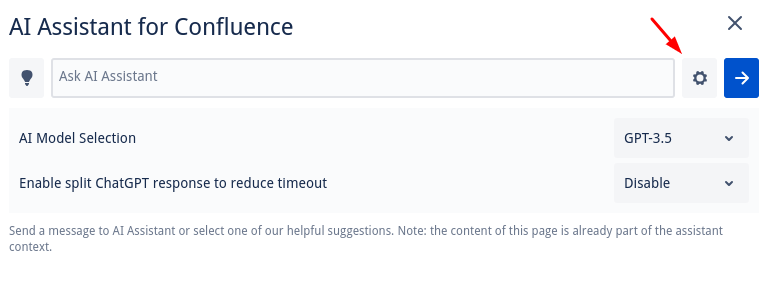
'Split Response' Option
The 'Split Response' option automatically limits the number of tokens that are sent in a single request to ChatGPT when it is enabled.
If this token limit is reached during a response, the client automatically triggers another request using the 'continue' reply. This ensures that the response is maintained while it is divided into smaller, manageable chunks. This option significantly reduces the risk of encountering a request timeout error due to a lengthy response.
When the 'Split Response' option is turned off, the client processes the full response, irrespective of the token count. However, this might lead to a timeout if the response is exceptionally long.
It's important to note that enabling this feature may incur additional costs related to input tokens as it sends the article as input for each request. However, this cost is often a worthwhile trade-off for the improved performance and assured stability it provides.